.mdファイルで執筆するデータドリブンなブログを作った
2023-01-02
前書き
年末テンションも相俟って,12月30日〜1月2日の突貫工事でブログを作った.
ただのブログを作るだけだと面白くないので,ブログ上で訪問者が行ったイベントをリアルタイムにデータ基盤に連携する機構も組み込んだ.
久し振りに分析目的以外のコードを書いたので,スムーズに手が進まなかったり,依然コードに粗が残っているが,なんとか公開できるレベルまで持っていけて安心.しかし,根詰めたので疲労困憊.
本投稿では,ブログを開設した背景とサービス構成,そして今後何を書くかについて執筆する.
ブログ開設の背景
スクラッチでデータドリブンなブログを開設した理由には以下3点がある. - 文才を身に付けるため - アウトプットする習慣を付けるため - データインジェストを実装する立場を理解したいため
まず自分は文章を書くのが遅くて下手過ぎる.学生時分から自覚はあったが,社会人になってからは何日経っても業務目標が書き終わらないことが多く,その度にこの欠点を痛感するようになった.他人に見られる文章を書く機会を増やせば少しずつ文才が磨かれていく,という希望的観測の下,ブログを書き始めることにした.
2つ目に,自分は今までインプットばかりしてアウトプットをほぼしないエンジニア?ライフを送ってきた.周りを見ても優秀な方でアウトプットしていない方は皆無.まずは形からということで,今年からはアウトプットする習慣をつけることにした.自分で作ったブログがあれば愛着も湧くし,長続きするだろうという目論見.
最後の理由は,データインジェストを実装する人の立場を理解するために,自分がインジェスト周りを実装してみたくなったから. 詳細は後述しているが,本ブログでは訪問者が行った行動をリアルタイムに記録する仕組みを設けている. 私は業務でユーザー行動データの分析を行なっているが,インジェストの設計/実装はしていない.分析する側のみの視点だけではなく,インジェストを実装する側の視点も持っておくことで,分析したい内容に合わせたインジェストの要件定義や設計,またはその作業依頼がしやすくなるのでは?と思った次第.
そんなこんなの事情で,スクラッチでブログを開設し,そこにデータインジェストの仕組みを作ってみよう!と思い立ったのが去年の12月30日.
本ブログのサービス構成
本ブログで使っているフレームワークやサービスは以下の通り.
Next.jsによるmarkdownブログ投稿サイトの構築
vercelから公式提供されているwith-dockerを使用した.repoをcloneする必要はなく,CLIで以下のコマンドを打つだけでDockerfileが含まれたnextのappを初期化できる.
npx create-next-app --example with-docker <YOUR-APP-NAME>
一点やや面倒な点は,この方法だとTypeScriptのオプション付きで初期化できないこと. この場合,空の
tsconfig.jsonをルートディレクトリに作成し,npm run dev すればOK.自動でtsconfig.jsonの中身が補完される.あとは.jsxを.tsxに変えるだけでts化完了.
肝心のmarkdownレンダリング部分は,以下の通りほぼremark依存.見出し作成の部分はremark-tocを使いたかったが,うまくunifiedに組み込目なかったため自分で書いた.時間があるときに原因を調べてunified に一本化したい.const extractLevel = (line: string) => { const m = line.match(/<h(\d)/); if(m === null){ return; } return parseInt(m[1]); }; const extractText = (line: string) => { const m = line.match(/<h\d>(.*)<\/h\d>/); if(m === null){ return; } return m[1]; }; const exatrctToc = (content: string) => { const sectionHeadings: SectionHeading[] = []; const lines = content.split('\n'); lines.forEach((line) => { if (line.startsWith('<h')) { const level = extractLevel(line); if(level === undefined){ return; } const text = extractText(line); if(text === undefined){ return; } const id = text.toLowerCase().replace(/ /g, '-'); sectionHeadings.push( new SectionHeading(level, text, id) ); } }); return sectionHeadings; }; const constructHtmlToc = (sectionHeadings: SectionHeading[]) => { let tocHtml = ''; let currentLevel = 0; sectionHeadings.forEach((sh) => { if (sh.level > currentLevel) { tocHtml += `<ol class="marker:text-white">`; } else if (sh.level < currentLevel) { tocHtml += `</ol>`; } tocHtml += `<li><a href="#${sh.id}">${sh.title}</a></li>`; currentLevel = sh.level; }); return tocHtml; }; const addIdsToHeadings = (content: string) => { const lines = content.split('\n'); lines.forEach((line: string, index: number) => { if (line.startsWith('<h')) { const level = extractLevel(line); if(level === undefined){ return; } const text = extractText(line); if(text === undefined){ return; } const id = text.toLowerCase().replace(/ /g, '-'); lines[index] = `<h${level} id="${id}">${text}</h${level}>`; } }); return lines.join('\n'); }; export async function getServerSideProps({ params }: Context) { const file = fs.readFileSync(`posts/${params.postName}.md`, 'utf-8'); const { data, content } = matter(file); const htmlContent = await unified() .use(remarkParse) .use(remarkRehype) .use(rehypeStringify) .process(content); const htmlToc = constructHtmlToc(exatrctToc(htmlContent.toString())); return { props: { frontMatter: data, content: addIdsToHeadings(htmlContent.toString()), toc: htmlToc, postName: params.postName, } }; }
なお投稿内容の管理にはGitHubのみを使用しており,データベースは使用していない.最初はCloud Firestoreなどを使って投稿内容や投稿内容に紐付くタグの管理をしようと思ったが,
- 投稿するのが自分一人であること
- 投稿頻度が頻繁ではない予定であること
- 当面,訪問者数が増える見込みはないこと🥲 を考慮すると,Node.js側でファイルを全探索して検索を行なってもさほどパフォーマンスが悪化することは無いだろうという楽観的な考えに落ち着いた.
投稿数が増えてきたり訪問者数が増えるようであれば,Firestoreの利用を検討する予定.
Cloud Runへのデプロイ
Cloud Runから「CREATE SERVICE」を押下し,「Continuously deploy new revisions from a source repository」を選択,「SET UP WITH CLOUD BUILD」を押下するとGitHubの認証とソースリポジトリの選択をする.これだけで push → deploy の自動化が完了.簡単.Cloud Run様々.
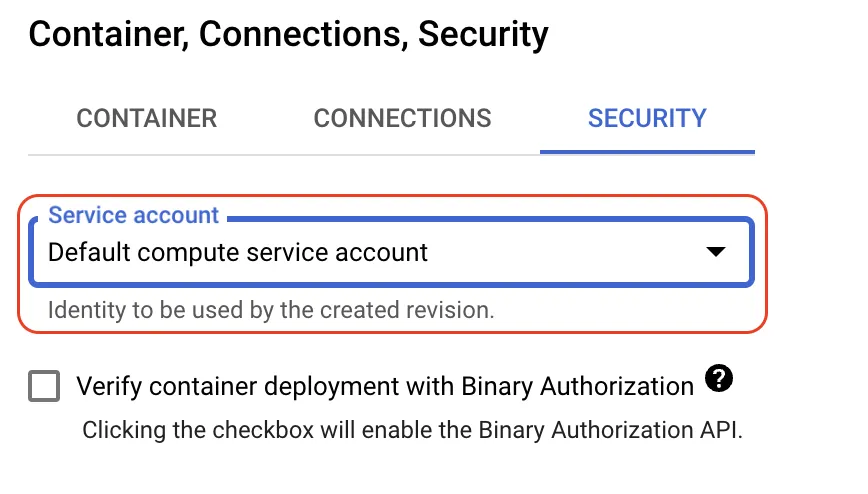
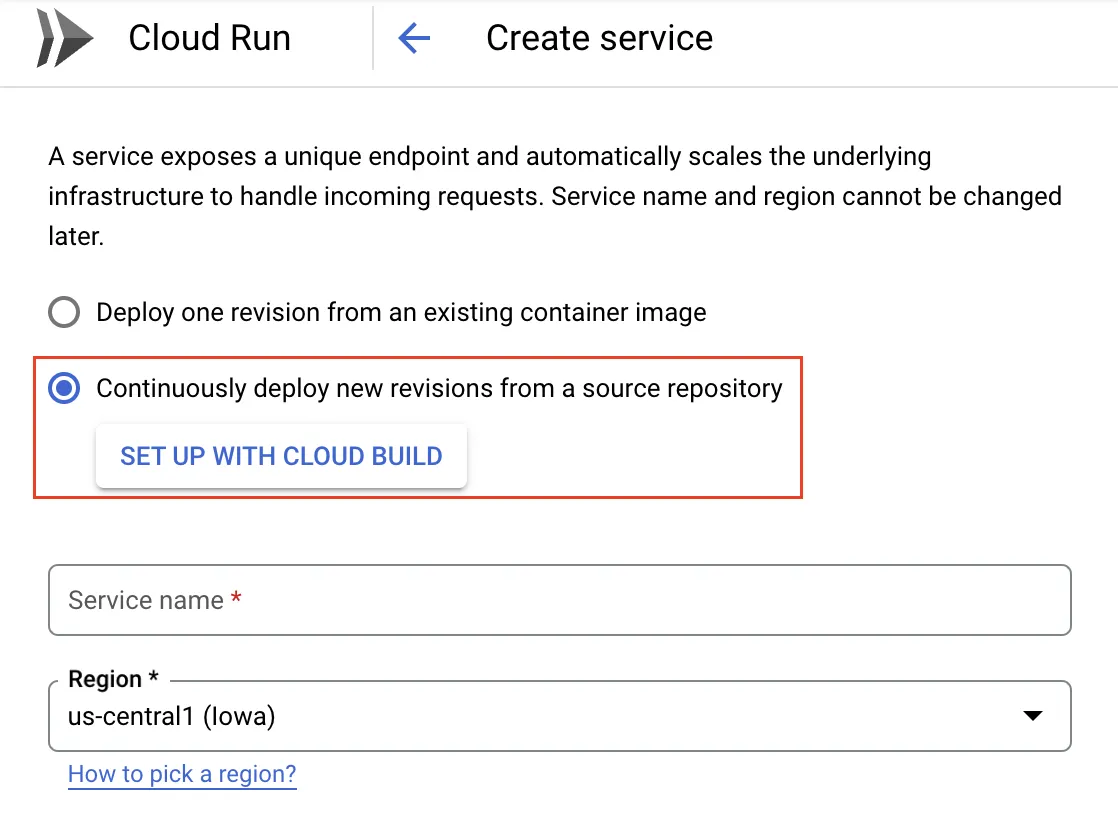 デプロイしたアプリからGCPのサービスを認証する場合(例えば本ブログのようにアプリ内でPub/Subトピックにメッセージを送信するなど)には,Cloud Runに構成したサービスに対してサービスアカウントを登録することができるので,認証情報の管理をせずにIAM側で権限設定を完結できるのもありがたい🙌
デプロイしたアプリからGCPのサービスを認証する場合(例えば本ブログのようにアプリ内でPub/Subトピックにメッセージを送信するなど)には,Cloud Runに構成したサービスに対してサービスアカウントを登録することができるので,認証情報の管理をせずにIAM側で権限設定を完結できるのもありがたい🙌
Pub/SubのBigQuery subscription
以前はPub/SubからDataFlowに流し,DataFlowからBigQueryにinsertする必要があったが,2022年7月からは表題のBigQuery subscriptionがPub/Subに導入された.これによりDataFlowを挟む必要がなくなった.
BigQuery subscriptionの構成に必要な手順は以下の3つ.
- Pub/Subのサービスアカウント( service-
@gcp-sa-pubsub.iam.gserviceaccount.com )に
roles/bigquery.dataEditorとroles/bigquery.metadataViewerを付与 - BigQueryにテーブルを作成
- Pub/Subにトピックとトピックに紐付くBigQuery subscriptionを作成 「2. 」でBigQueryに作成するテーブルは送信するデータの種類やトピックのスキーマと整合性を取る必要がある点に注意が必要.
BigQuery subscriptionによって投入できるデータの種類には「Pub/Subトピックで使用しているスキーマと同一構造のデータ」,「Pub/Subメッセージのメタデータ」,及びその両方の3つだが,例えばPub/Subメッセージのメタデータを送信する場合には,BigQueryで以下の列構造を持つテーブルを作成する必要がある.
- subscription_name ( STRING )
- message_id ( STRING )
- publish_time ( TIMESTAMP )
- data ( BYTES, STRING or JSON )
- attributes ( STRING or JSON )
因みに,BigQuery subscriptionを使用する場合にはメッセージのメタデータを送信することを強く推奨する.BigQuery subscriptionはpush型のsubscriptionである都合上,同一のデータが複数回BigQuery内に連携される可能性がある.そこで,
message_idをメタデータとして送信しておくと,データの重複を省きやすくなるのである.
また,前掲の
dataフィールドにはほぼ任意のデータを入れられるので,ミニマルなアプリであればメタデータの送信のみで柔軟にケースに対応できる.本ブログでもメタデータだけ送信する方式にしている.
BigQuery subscriptionについて詳しく知りたい方はGCPの公式ドキュメントを読むと良い.一番分かりやすい.後書き
とりあえずミニマルにブログを作ってみたが,あって当たり前の機能がまだない.
例えば,
- 自然言語による記事の検索
- タグによる記事の検索/絞り込み
- コメント機能 などなど.
この辺りは突貫工事の粗を潰しながら,着々と作っていきたい.
今後の投稿予定
今回は初回ということもあって割と長めの投稿をしたが,基本的にはライトな投稿を多めにする予定.内容は特に限定せず,技術関連や趣味に関するものまで徒然なるままに書こうかと.
ではでは.